



版權說明:本文檔由用戶提供并上傳,收益歸屬內容提供方,若內容存在侵權,請進行舉報或認領
文檔簡介
1、基于DTW算法的語音識別原理與實現【摘要】以一個能識別數字09的語音識別系統的實現過程為例,闡述了基于DTW算法的特定人孤立詞語音識別的基本原理和關鍵技術。其中包括對語音端點檢測方法、特征參數計算方法和DTW算法實現的詳細討論,最后給出了在Matlab下的編程方法和實驗結果。【關鍵字】語音識別;端點檢測;MFCC系數;DTW算法【中圖分類號】TN912.34【文獻標識碼】A0 引言自計算機誕生以來,通過語音與計算機交互一直是人類的夢想,隨著計算機軟硬件和信息技術的飛速發展,人們對語音識別功能的需求也更加明顯和迫切。語音識別技術就是讓機器通過識別和理解過程把人類的語音信號轉變為相應的文本或命令的
2、技術,屬于多維模式識別和智能計算機接口的范疇1。傳統的鍵盤、鼠標等輸入設備的存在大大妨礙了系統的小型化10,而成熟的語音識別技術可以輔助甚至取代這些設備。在PDA、智能手機、智能家電、工業現場、智能機器人等方面語音識別技術都有著廣闊的前景。語音識別技術起源于20世紀50年代,以貝爾實驗室的Audry系統為標志1,8。先后取得了線性預測分析(LP)、動態時間歸整(DTW)、矢量量化(VQ)、隱馬爾可夫模型(HMM)等一系列關鍵技術的突破和以IBM的ViaVoice、Microsoft的VoiceExpress9為代表的一批顯著成果。國內的語音識別起步較晚,1987年開始執行國家863計劃后語音識
3、別技術才得到廣泛關注。具有代表性的研究單位為清華大學電子工程系與中科院自動化研究所模式識別國家重點實驗室,中科院聲學所等9。其中中科院自動化所研制的非特定人連續語音聽寫系統和漢語語音人機對話系統,其準確率和系統響應率均可達90%以上1。常見的語音識別方法有動態時間歸整技術(DTW)、矢量量化技術(VQ)、隱馬爾可夫模型(HMM)、基于段長分布的非齊次隱馬爾可夫模型(DDBHMM)和人工神經元網絡(ANN)1,9。DTW是較早的一種模式匹配和模型訓練技術,它應用動態規劃的思想成功解決了語音信號特征參數序列比較時時長不等的難題,在孤立詞語音識別中獲得了良好性能。雖然HMM模型和ANN在連續語音大詞
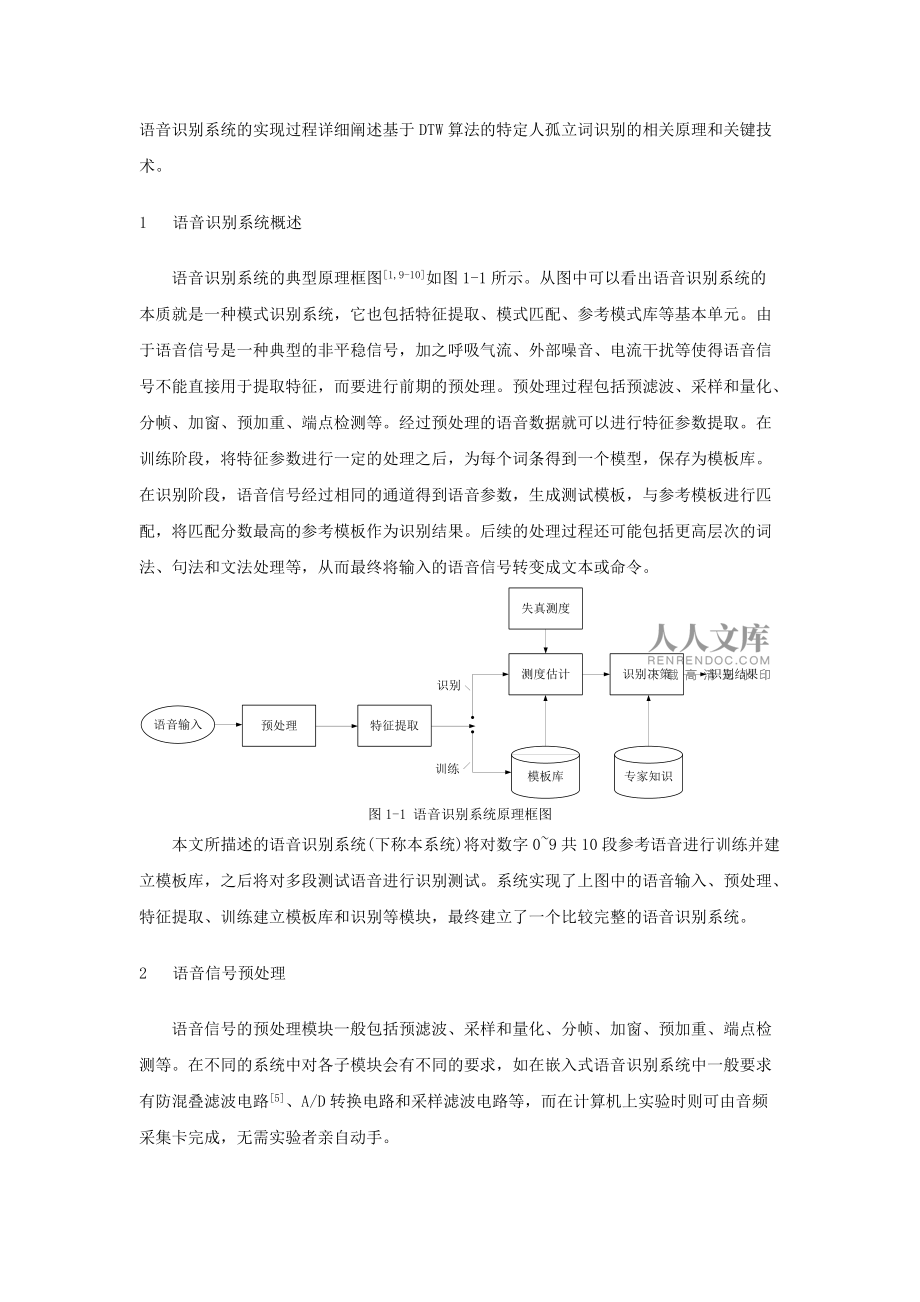
4、匯量語音識別系統優于DTW,但由于DTW算法計算量較少、無需前期的長期訓練,也很容易將DTW算法移植到單片機、DSP上實現語音識別且能滿足實時性7要求,故其在孤立詞語音識別系統中仍然得到了廣泛的應用。本文將通過能識別數字09的語音識別系統的實現過程詳細闡述基于DTW算法的特定人孤立詞識別的相關原理和關鍵技術。1 語音識別系統概述語音識別系統的典型原理框圖1,9-10如圖1-1所示。從圖中可以看出語音識別系統的本質就是一種模式識別系統,它也包括特征提取、模式匹配、參考模式庫等基本單元。由于語音信號是一種典型的非平穩信號,加之呼吸氣流、外部噪音、電流干擾等使得語音信號不能直接用于提取特征,而要進行
5、前期的預處理。預處理過程包括預濾波、采樣和量化、分幀、加窗、預加重、端點檢測等。經過預處理的語音數據就可以進行特征參數提取。在訓練階段,將特征參數進行一定的處理之后,為每個詞條得到一個模型,保存為模板庫。在識別階段,語音信號經過相同的通道得到語音參數,生成測試模板,與參考模板進行匹配,將匹配分數最高的參考模板作為識別結果。后續的處理過程還可能包括更高層次的詞法、句法和文法處理等,從而最終將輸入的語音信號轉變成文本或命令。圖1-1 語音識別系統原理框圖本文所描述的語音識別系統(下稱本系統)將對數字09共10段參考語音進行訓練并建立模板庫,之后將對多段測試語音進行識別測試。系統實現了上圖中的語音輸
6、入、預處理、特征提取、訓練建立模板庫和識別等模塊,最終建立了一個比較完整的語音識別系統。2 語音信號預處理語音信號的預處理模塊一般包括預濾波、采樣和量化、分幀、加窗、預加重、端點檢測等。在不同的系統中對各子模塊會有不同的要求,如在嵌入式語音識別系統中一般要求有防混疊濾波電路5、A/D轉換電路和采樣濾波電路等,而在計算機上實驗時則可由音頻采集卡完成,無需實驗者親自動手。2.1 語音信號采集在Matlab環境中語音信號的采集可使用wavrecord(n,fs,ch,dtype)函數錄制,也可使用Windows的“錄音機”程序錄制成.wav文件然后使用wavread(file) 函數讀入。為了進行批
7、量的的訓練和識別處理,本系統的訓練語音和識別語音全部使用“錄音機”程序預先錄制。如圖2-1所示為數字0的訓練語音00.wav的信號波形圖,第(I)幅圖為完整的語音波形,第(II)、(III)幅圖分別為語音的起始部分和結束部分的放大波形圖。圖2-1 語音00.wav的信號波形圖2.2 分幀語音信號是一種典型的非平穩信號,它的均值函數u(x)和自相關函數R(xl,x2)都隨時間而發生較大的變化5,9。但研究發現,語音信號在短時間內頻譜特性保持平穩,即具有短時平穩特性。因此,在實際處理時可以將語音信號分成很小的時間段(約1030ms5,7),稱之為“幀”,作為語音信號處理的最小單位,幀與幀的非重疊部
8、分稱為幀移,而將語音信號分成若干幀的過程稱為分幀。分幀小能清楚地描繪語音信號的時變特征但計算量大;分幀大能減少計算量但相鄰幀間變化不大,容易丟失信號特征。一般取幀長20ms,幀移為幀長的1/31/2。在Matlab環境中的分幀最常用的方法是使用函數enframe(x,len,inc),其中x為語音信號,len為幀長,inc為幀移。在本系統中幀長取240,幀移取80。2.3 預加重對于語音信號的頻譜,通常是頻率越高幅值越小,在語音信號的頻率增加兩倍時,其功率譜的幅度下降6dB。因此必須對高頻進行加重處理,一般是將語音信號通過一個一階高通濾波器1-0.9375z-1,即為預加重濾波器。其目的是濾除
9、低頻干擾,特別是50Hz到60Hz的工頻干擾,將對語音識別更為有用的高頻部分進行頻譜提升。在計算短時能量之前將語音信號通過預加重濾波器還可起到消除直流漂移、抑制隨機噪聲和提升清音部分能量的效果。預加重濾波器在Matlab中可由語句x=filter(1-0.9375,1,x)實現。2.4 加窗為了保持語音信號的短時平穩性,利用窗函數來減少由截斷處理導致的Gibbs效應。用的最多的三種為矩形窗、漢明窗(Hamming)和漢寧窗(Hanning)。其窗函數如下,式中的N為窗長,一般等于幀長。矩形窗: 漢明窗(Hamming):漢寧窗(Hanning):WR =1 (0nN-1)0 (Other)WH
10、M =0.5-0.46cos(2n/(N-1) (0nN-1)0 (Other) WHN =0.5-0.5cos(2n/(N-1) (0nN-1)0 (Other)(2-1)(2-2)(2-3)窗口的選擇非常重要,不同的窗口將使能量的平均結果不同。矩形窗的譜平滑,但波形細節丟失;而漢明窗則剛好相反,可以有效克服泄漏現象,具有平滑的低通特性4-6。因此,在語音的時域處理方法中,一般選擇矩形窗,而在語音的頻域處理方法中,一般選擇漢明窗或漢寧窗5-6。在Matlab中要實現加窗即將分幀后的語音信號乘上窗函數,如加漢明窗即為x=x.*hamming(N)。本系統中的端點檢測采用時域方法故加矩形窗,計算
11、MFCC系數時加漢明窗。3 端點檢測在基于DTW算法的語音識別系統中,無論是訓練和建立模板階段還是在識別階段,都先采用端點檢測算法確定語音的起點和終點。語音端點檢測是指用計算機數字處理技術從包含語音的一段信號中找出字、詞的起始點及結束點,從而只存儲和處理有效語音信號。對漢語來說,還可進一步找出其中的聲母段和韻母段所處的位置。語音端點檢測是語音分析、合成和識別中的一個重要環節,其算法的優劣在某種程度上也直接決定了整個語音識別系統的優劣。進行端點檢測的基本參數主要有短時能量、幅度、過零率和相關函數等。端點檢測最常見的方法是短時能量短時過零率雙門限端點檢測,近年來在此基礎上發展出的動態窗長短時雙門限
12、端點檢測方法4也被廣泛使用。3.1 短時能量語音和噪聲的主要區別在它們的能量上,如圖3-1(III) 和圖3-2(III)所示。語音段的能量比噪聲段的大,語音段的能量是噪聲段能量疊加語音聲波能量的和。對第n幀語音信號的短時能量En的定義為: (3-1)xn為原樣本序列在窗函數所切取出的第n段短時語音,N為幀長。因為在計算時使用的是信號的平方,故將En作為一個度量語音幅度值變化的函數有一個缺陷,即對高電平非常敏感。因此在許多場合會將En用下式來代替: (3-2)這樣就不會因為取平方而造成信號的小取樣值的大取樣值出現較大差異。本系統中窗函數為WR(見式2-1),N為240。圖3-1(I)和圖3-2
13、(I)分別為數字0的訓練語音00.wav和數字4的訓練語音40.wav的波形,圖3-1(III)和圖3-2(III)分別為它們的短時能量。圖3-1 語音00.wav的時域分析參數圖3-2 語音40.wav的時域分析參數3.2 短時過零率短時過零表示一幀語音信號波形穿過橫軸(零電平)的次數。對于連續語音信號,過零意味著時域波形通過時間軸;而對于離散信號,如果相鄰的取樣值的改變符號則稱為過零。過零率就是樣本改變符號次數,定義語音信號壽(m)的短時過零率Zn為: (3-3)1 (x0)-1 (x0)sgnx= (3-4)清音的能量多集中在較高的頻率上,它的平均過零率要高于濁音,故短時過零率可以用來區
14、分清音、濁音以及無聲。圖3-1(II)和圖3-2(II)分別為數字0的訓練語音00.wav和數字4的訓練語音40.wav的短時過零率。從圖中可以看到清音s的過零率明顯高于其后的i音,有聲段過零率明顯高于無聲段,但在鼻音階段過零率迅速滑落到無聲水平而能量值則是緩慢下滑。在實際應用時并不能通過式3-3直接計算過零率,因為在無聲段噪聲使語音波形在0值附近來回擺動,導致計算出的過零率和有聲段的區別并不十分明顯。比較簡單的解決方法是設定一個差的閾值,使不僅xn(m)*xn(m-1) 。在本系統中經多次試驗取定=0.01。3.3 雙門限端點檢測雙門限端點檢測顧名思義需要兩級檢測,即短時能量檢測和短時過零率
15、檢測。在開始檢測之前需要設定4個門限,即分別為短時能量和短時過零率各設置一個高門限和一個低門限:EHigh、ELow和ZHigh、ZLow。整個語音端點檢測分為四部分:靜音段、過度段、語音段、結束段。在靜音段中如果能量或過零率有一個超過了其低門限,則認為進入了過度段。在過度段中,由于參數數值較小,還不能確定是否真的進入語音段,只有兩個參數的其中一個超越了高門限才被認為是進入語音段。當參數降至低門限則認為進入結束。此外,還有兩種可能會引起端點檢測的誤判:一是短時噪音引起的誤判,此時則需要引入最小語音長度門限進行噪聲判定,即語音段時間小于一定數值則認定為是噪聲,重新回到靜音段,本系統設為20ms;
16、二是語音中字與字的時間空隙引起的誤判,此時需要設定最大靜音長度門限來降低識別的錯誤率,本系統所訓練和識別的都為單字,故無需設置此門限。在雙門限端點檢測中4個門限的設定至關重要,門限設定的好壞將直接影響端點檢測的結果。門限值的設置還沒有一個通用可靠的方法,需要根據經驗和特定環境進行調整。常見的方法有最大值乘上某個比率、中位值乘上某個比率、最小值乘上某個常數、前三幀平均值乘上某個常數等。本系統中EHigh,ELow,ZHigh,ZLow的取值分別為:EHigh=max(min(amp)*10,mean(amp)*0.2,max(amp)*0.1); ZHigh=max(round(max(zcr)
17、*0.1),5);ELow=min(min(amp)*10,mean(amp)*0.2,max(amp)*0.1); ZLow=max(round(mean(zcr)*0.1),3);圖3-3和圖3-4分別是數字0的訓練語音00.wav和數字4的訓練語音40.wav的端點檢測結果,紅線之間的部分為檢測出的語音有聲段。圖3-3 語音00.wav的端點檢測結果圖3-4 語音40.wav的端點檢測結果4 語音識別參數提取經過預處理的語音數據就可以進行特征參數提取,特征參數的好壞將直接影響系統的性能和效率,對特征參數的要求包括9-10:(1) 提取的特征參數能有效地代表語音特征,具有很好的區分性;(2
18、) 各階參數之間有良好的獨立性;(3) 特征參數要計算方便,最好有高效的計算方法,以保證語音識別的實時實現。4.1 LPC與LPCC系數LPC(Linear Prediction Coefficient,線性預測系數)模擬人發音器官的聲管模型,是一種基于語音合成的參數模型。在語音識別系統中很少直接使用LPC系統,而是由LPC系數推出的另一種參數LPCC。LPCC(Linear Prediction Cepstrum Coefficient,線性預測倒譜系數)是LPC在倒譜域中的表示。該特征是基于語音信號為自回歸信號的假設,利用線性預測分析獲得倒譜系數。LPCC的優點是計算量小,易于實現,對元音
19、有較好的描述能力,缺點是對輔音描述能力較差。4.2 MFCC系數LPC模型是基于發音模型建立的,LPCC系數也是一種基于合成的系數,這種參數沒有充分利用人耳的聽覺特性。實際上,人的聽覺系統是一個特殊的非線性系統,它響應不同頻率信號的靈敏度是不同的,基本上是一個對數的關系9-10。近年來,一種能夠比較充分利用人耳的這種特殊感知特性的系數得到了廣泛應用,這就是Mel尺度倒譜系數(Mel-scaled Cepstrum Coefficients,簡稱MFCC)。大量研究表明,MFCC系數能夠比LPCC參數更好地提高系統的識別性能10。MFCC系數的計算是以“bark”為其頻率基準的,它和線性頻率的轉
20、換關系是: (4-1)MFCC系數也是按幀計算的,首先要通過FFT得到該幀信號的功率譜S(n),轉換為Mel頻率下的功率譜。這需要在計算之前先在語音的頻譜范圍內設置若干個帶通濾波器:Hm(n) m=0,1,M-1; n=0,1,N/2-1 (4-2)M為濾波器的個數,通常取24,與臨界帶的個數一樣;N為一幀語音信號的點數,為了計算FFT的方便,通常取256。濾波器在頻域上為簡單的三角形,其中心頻率fm在Mel頻率軸上是均勻分布的。如圖4-1所示為Mel尺度濾波器組,包含24個濾波器,語音信號幀長取為256個點,語音信號的采樣頻率為8KHz,。圖4-1 Mel 尺度濾波器組帶通濾波器的系數事先計
21、算好,在計算MFCC系數是直接使用。MFCC系數的計算過程如下:(1) 預處理:確定每一幀語音采樣序列的長度(如N=256),并對每幀序列s(n)進行預加重、分幀和加窗處理;(2) 計算離散功率譜:對預處理的每幀進行離散FFT變換得到其頻譜,再取模的平方作為離散功率譜S(n);(3) 將功率譜通過濾波器組:計算S(n)通過M個Hm(n)后所得的功率值,即計算S(n)和Hm(n)在各離散頻率點上的乘積之和,得到M個參數Pm,m=0,1,M-1;(4) 取對數:計算Pm的自然對數,得到Lm,m=0,1,M-1;(5) 離散余弦變換:對Lm計算其離散余弦變換,得到D m,m=0,1,M-1,舍去代表
22、直流成份的D0,取D1,D2,Dk作為MFCC參數。具體流程可以用框圖4-2表示為:圖4-2 MFCC系數計算流程圖在Matlab環境中計算M個濾波器的系數可以調用語音工具箱voicebox中的函數melbankm(m,n,fs)來實現,其中m為濾波器的個數,n為語音幀長,fs為采樣頻率。計算mfcc系數的函數為melcepst(s,fs),s為語音信號。5 DTW算法實現DTW(Dynamic Time Warping,動態時間規整)是語音識別中較為經典的一種算法。在實現小詞匯表孤立詞識別系統時,其識別率及其它指標與HMM算法實現幾乎等同9。又由于HMM算法復雜,在訓練階段需要提供大量的語音
23、數據通過反復計算才能得到模型參數,而DTW算法本身既簡單又有效,因此在特定的場合下獲得了廣泛的應用。5.1 匹配模式模板匹配方法的語音識別算法需要解決的一個關鍵問題是說話人對同一個詞的兩次發音不可能完全相同,這些差異不僅包括音強的大小、頻譜的偏移,更重要的是發音時音節的長短不可能完全相同,而且兩次發音的音節往往不存在線性對應關系。設參考模板有M幀矢量R(1),R(2),R(m),R(M),R(m)為第m幀的語音特征矢量,測試模板有N幀矢量T(1),T(2),T(n),T(N),T(n)是第n幀的語音特征矢量。d(T(in),R(im)表示T中第in幀特征與R中im幀特征之間的距離,通常用歐幾里
24、德距離9-10表示。直接匹配是假設測試模板和參考模板長度相等,即in=im;線性時間規整技術假設說話速度是按不同說話單元的發音長度等比例分布的,即。顯然,這兩種假設都不符合實際語音的發音情況,我們需要一種更加符合實際情況的非線性時間規整技術。如圖5-1所示為三種匹配模式對同一詞兩次發音的匹配距離(兩條曲線間的陰影面積),顯然D3D2D1。待測模式T參考模式Rttttt直接匹配D1(T,R)線性匹配D2(T,R)非線性匹配D3(T,R)圖5-1 三種匹配模式對比5.2 DTW算法原理DTW是把時間規整和距離測度計算結合起來的一種非線性規整技術,它尋找一個規整函數im=(in),將測試矢量的時間軸
25、n非線性地映射到參考模板的時間軸m上,并使該函數滿足: (5-1)D就是處于最優時間規整情況下兩矢量的距離。由于DTW不斷地計算兩矢量的距離以尋找最優的匹配路徑,所以得到的是兩矢量匹配時累積距離最小所對應的規整函數,這就保證了它們之間存在的最大聲學相似性。DTW算法的實質就是運用動態規劃的思想,利用局部最佳化的處理來自動尋找一條路徑,沿著這條路徑,兩個特征矢量之間的累積失真量最小,從而避免由于時長不同而可能引入的誤差DTW算法要求參考模板與測試模板采用相同類型的特征矢量、相同的幀長、相同的窗函數和相同的幀移。為了使動態路徑搜索問題變得有實際意義,在規整函數上必須要加一些限制,不加限制使用式(5
26、-1)找出的最優路徑很可能使兩個根本不同的模式之間的相似性很大,從而使模式比較變得毫無意義。通常規整函數必須滿足如下的約束條件:(1) 邊界限制:當待比較的語音已經進行精確的端點檢測,在這種情況下,規整發生在起點幀和端點幀之間,反映在規整函數上就是: (5-2)(2) 單調性限制由于語音在時間上的順序性,規整函數必須保證匹配路徑不違背語音信號各部分的時間順序。即規整函數必須滿足單調性限制: (5-3)(3) 連續性限制有些特殊的音素有時會對正確的識別起到很大的幫助,某個音素的差異很可能就是區分不同的發聲單元的依據,為了保證信息損失最小,規整函數一般規定不允許跳過任何一點。即: (5-4)DTW
27、算法的原理圖如圖5-2,把測試模板的各個幀號n=1N在一個二維直角坐標系中的橫軸上標出,把參考模板的各幀m=1M在縱軸上標出,通過這些表示幀號的整數坐標畫出一些縱橫線即可形成一個網格,網格中的每一個交叉點(ti,rj)表示測試模式中某一幀與訓練T(1)=1時間規整函數1 2 3 in N R1 2 im M (N)=M圖5-2 DTW算法原理圖(in , im)(in-1 , im)(in-1 , im-1)(in-1 , im-2)圖5-3 局部約束路徑模式中某一幀的交匯。DTW算法分兩步進行,一是計算兩個模式各幀之間的距離,即求出幀匹配距離矩陣,二是在幀匹配距離矩陣中找出一條最佳路徑。搜索
28、這條路徑的過程可以描述如下:搜索從(1,1)點出發,對于局部路徑約束如圖5-3,點(in,im)可達到的前一個格點只可能是(in-1,im)、(in-1,im-l)和(in-1,im-2)。那么(in,im)一定選擇這三個距離中的最小者所對應的點作為其前續格點,這時此路徑的累積距離為:D(in,im)=d(T(in),R(im)+minD(in-1,im),D(in-1,im-1),D(in-1,im-2) (5-5)這樣從(l,1)點出發(令D(1,1)=0)搜索,反復遞推,直到(N,M)就可以得到最優路徑,而且D(N,M)就是最佳匹配路徑所對應的匹配距離。在進行語音識別時,將測試模板與所有
29、參考模板進行匹配,得到的最小匹配距離 Dmin(N,M)所對應語音即為識別結果。5.3 DTW算法改進DTW算法雖然簡單有效,但是動態規劃方法需要存儲較大的矩陣,直接計算將會占據較大的空間,計算量也比較大。由圖5-3的局部路徑約束可知DTW算法所動態搜索的空間其實并不是整個矩形網格,而是局限于對角線附近的帶狀區域9,如圖5-4所示,許多點實際上是達不到的。因此,在實際應用中會將DTW算法進行一些改進以減少存儲空間和降低計算量。常見的改進方法有搜索寬度限制、放寬端點限制等。5.3.1 搜索寬度限制以圖5-3中的局部約束路徑為例,待測模板軸上每前進一幀,對于點(in,im)只需要用到前一列(in-
30、1,im)、(in-l,im-l)和(in-1,im-2)三點的累積距離,也就是im-1和im-2兩行的累積距離。整個DTW算法的計算過程遞推循環進行,也就是每一行中的格點利用前兩行格點的累積距離計算該點的累積距離的過程。基于這種循環遞推計算,只需分配3N的存儲空間重復使用,而不需要保存幀匹配距離矩陣和所有的累積距離矩陣。又由于DTW算法的動態搜索寬度局限于對角線附近的帶狀區域,假設其寬度為width,如圖5-4和圖5-6,則實際只需分配3width的存儲空間即可。圖5-4 帶狀搜索區域 圖5-5 搜索寬度限制存儲空間5.3.2 放寬端點限制普通DTW對端點檢測比較敏感,端點信息是作為一組獨立
31、的參數提供給識別算法的。它要求兩個比較模式起點對起點,終點對終點,對端點檢測的精度要求比較高。當環境噪聲比較大或語音由摩擦音構成時,端點檢測不易進行,這就要求在動態時間規整過程中給以考慮。放松端點限制方法不嚴格要求端點對齊,克服由于端點算法不精確造成的測試模式和參考模式起點終點不能對齊的問題。一般情況下,起點和終點在縱橫兩個方向只要放寬2-3幀就可以,也就是起點可以在(1,1),(l,2),(1,3),(2,1),(3,l),終點類似。如圖5-6。圖5-6 改進的DTW算法原理圖Ck=(ik, jk)C1=(1, 1)CK=(I, J)j = i - rj = i + r時間規整函數 width ijt1 t2 t3 ti tI TRr1 r2 rj rJ 在放寬端點限制的DTW算法中,累積距離矩陣中的元素(1,l),(l,2),(l,3),(2,
溫馨提示
- 1. 本站所有資源如無特殊說明,都需要本地電腦安裝OFFICE2007和PDF閱讀器。圖紙軟件為CAD,CAXA,PROE,UG,SolidWorks等.壓縮文件請下載最新的WinRAR軟件解壓。
- 2. 本站的文檔不包含任何第三方提供的附件圖紙等,如果需要附件,請聯系上傳者。文件的所有權益歸上傳用戶所有。
- 3. 本站RAR壓縮包中若帶圖紙,網頁內容里面會有圖紙預覽,若沒有圖紙預覽就沒有圖紙。
- 4. 未經權益所有人同意不得將文件中的內容挪作商業或盈利用途。
- 5. 人人文庫網僅提供信息存儲空間,僅對用戶上傳內容的表現方式做保護處理,對用戶上傳分享的文檔內容本身不做任何修改或編輯,并不能對任何下載內容負責。
- 6. 下載文件中如有侵權或不適當內容,請與我們聯系,我們立即糾正。
- 7. 本站不保證下載資源的準確性、安全性和完整性, 同時也不承擔用戶因使用這些下載資源對自己和他人造成任何形式的傷害或損失。
最新文檔
- 建房橫梁出售合同范本
- 商標使用協議合同范本
- 宣傳稿件印刷合同范本
- 品牌產品定制合同范本
- 口罩制作合同范本
- 電信外包員工合同范本
- 賣房返租合同范本
- 品牌商鋪轉讓合同范本
- 塑膠公司購銷合同范本
- 承包國道項目合同范本
- DL/T 5155-2016 220kV~1000kV變電站站用電設計技術規程
- 護理倫理學教學課件第三章護患關系倫理
- 工業固體廢物協同礦山地質環境修復治理項目環評報告書
- 表面粗糙度儀操作作業指導書
- 部編版小學語文五年級下冊第4單元基礎知識檢測卷-(含答案)
- Unit 5 Understanding ideas Nature in architecture -高中英語外研版(2019)選擇性必修第三冊
- 王陽明心學課件
- GB/T 11982.2-2015聚氯乙烯卷材地板第2部分:同質聚氯乙烯卷材地板
- 消化性潰瘍理論知識試題含答案
- 學校食堂廉政風險責任書
- 中國石油大學(華東)PPT模板
評論
0/150
提交評論